
Building a MotherDuck file browser: adding preview

Today let’s extend our MotherDuck S3 file browser with a way to see the contents of an individual spreadsheet file right on the screen.
To recap, yesterday we built a basic S3 file browser that:
Is purely front end and framework-less vanilla JS, using MotherDuck’s wasm-client
Allows users to plug in their own tokens / bring-your-own-database
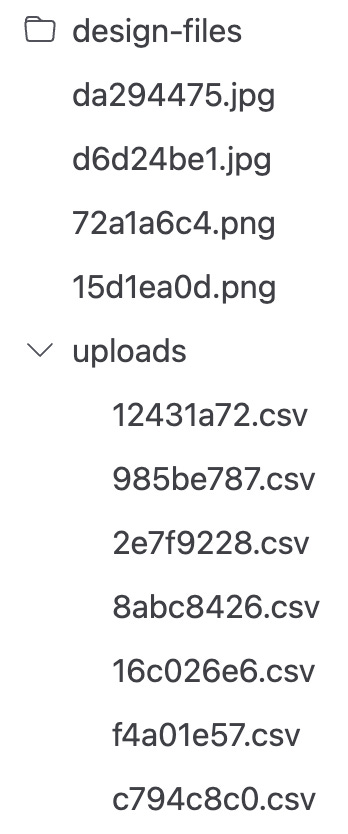
Offers file browsing with an interactive tree view:
Let’s dive in!
Getting a file path and responding to clicks
When the user clicks on a file in the tree browser, our app will need to gather up the full path to that file in S3 so that we can read it. Right now we aren’t preserving that full path anywhere; it’s just represented by the DOM structure of the sl-tree. This is another good method to delegate to Claude:
getFullPath (treeItem) {
const parts = [];
// Start with current item's text content, trimmed to remove extra spaces
parts.push(treeItem.textContent.trim());
// Walk up the tree looking for parent sl-tree-items
let current = treeItem;
while (current) {
// Find the next parent sl-tree-item
current = current.parentElement.closest('sl-tree-item');
if (current) {
// Get just the folder name by:
// 1. Getting the text content
// 2. Removing children's text by removing all nested sl-tree-items
const clone = current.cloneNode(true);
clone.querySelectorAll('sl-tree-item').forEach(el => el.remove());
const folderName = clone.textContent.trim();
parts.unshift(folderName);
}
}
return `s3://${this.bucket}/${parts.join('/')}`;
}Let’s add a click handler on the top-level sl-tree that figures out:
what node we actually clicked on;
whether that node is (or is within) an
sl-tree-item;and whether that
sl-tree-itemrepresents a file or an expandable folder.
If it’s a file, we’ll get its full path so that we can read from it:
async handleFileClick (e) {
const item = e.target.closest('sl-tree-item');
if (!item) {
/* If the click was not within a tree item, we don't want it */
return;
}
if (item.querySelector('sl-tree-item')) {
/* If the clicked-on tree item has tree items, it's not a file, so we don't want it */
return;
}
const filePath = this.getFullPath(item);
} /* In our code that built the tree and inserted it
into the DOM in the first place: */
document.body.append(div);
div.querySelector('sl-tree')
.addEventListener('click', e => app.handleFileClick(e));Reading a file with MotherDuck
Now that we have a full s3://bucket/path/to/file.ext path we can just read from it with a MotherDuck query, treating the quoted file name as a table:
const filePath = this.getFullPath(item);
const { data } = await this.connection.evaluateQuery(`
SELECT * FROM '${filePath}'
`);But wait — our bucket might not just be CSVs. It might also have images, text files, and other things that MotherDuck can’t read. So we’ll check the clicked-on file’s extension before we try to query it:
const filePath = this.getFullPath(item);
if (!filePath.endsWith('.csv')) {
/* The clicked-on tree item doesn't look like a data file, so we don't want it */
return;
}
e.stopPropagation();
const { data } = await this.connection.evaluateQuery(`
SELECT * FROM '${filePath}'
`);But wait again — DuckDB isn’t limited to CSVs. It can also read Parquet files and even JSON! Let’s handle all three:
const filePath = this.getFullPath(item);
const validExtensions = ['csv', 'parquet', 'json'],
suffix = filePath.split('.').pop().toLowerCase();
if (validExtensions.indexOf(suffix) === -1) {
/* The clicked-on tree item doesn't look like a data file, so we don't want it */
return;
}
e.stopPropagation();
const { data } = await this.connection.evaluateQuery(`
SELECT * FROM '${filePath}'
`);
const rows = data.toRows();Displaying the file contents
That SQL query followed by .toRows() will give us the full contents of the chosen file as an array of objects.
Column types — strings, numbers, booleans, timestamps, lists, and so on — within each object will be inferred and converted to JS primitives or custom objects as needed, which is useful if we need to run logic in JS against them. But … we just want to display the contents in HTML. There are two MotherDuck wasm-client methods that will be helpful here:
data.columnNames()will return an array of strings that tell us the names of the columns and what order to display them in.Within a given row, all attribute values are guaranteed to implement
.toString()so we can always ask them how they want to be rendered in HTML. (There’s one exception: if the query returnsNULLfor any particular cell, we just get back a JavaScriptnullthere. The JavaScriptnullobject does not implement.toString(), so we need to specifically handle that case.)
With that in mind, we can convert our query result to an HTML table:
buildTableFromQueryResult (data) {
const columns = data.columnNames(),
rows = data.toRows();
const table = document.createElement('table');
table.innerHTML = `<thead><tr></tr></thead><tbody></tbody>`;
table.querySelector('thead tr').innerHTML = columns.map(
column => `<th>${column}</th>`
).join('\n');
const tbody = table.querySelector('tbody');
rows.forEach(row => {
const tr = document.createElement('tr');
tr.innerHTML = columns.map(
column => row[column] === null ? '' : row[column].toString()
).map(
cell => `<td>${cell}</td>`
).join('\n');
tbody.append(tr);
});
return table;
}Since we’re already using Shoelace we may as well put our HTML table in a modal drawer:
const { data } = await this.connection.evaluateQuery(`
SELECT * FROM '${filePath}'
`);
const table = this.buildTableFromQueryResult(data);
/* Make sure we're cleaning up any old closed drawers first */
Array.from(document.querySelectorAll('sl-drawer.query-result')).forEach(el => el.remove());
const drawer = document.createElement('sl-drawer');
drawer.classList.add('query-result');
drawer.open = true;
drawer.style.setProperty('--size', '75vw');
drawer.append(table);
document.body.append(drawer);And that’s all! We’ve now got a nice table that slides out from a side drawer to display what’s in any CSV, Parquet, or JSON file we might find while browsing our S3 bucket:

Next steps
I’ll continue building this app in future posts — for example, now that we’re displaying the file in a table, it would be great to add MotherDuck-powered sorting and filtering. We’ll also need to circle back to some error and edge case handling (including filenames with single quotes) and should probably implement pagination throughout, in case we click on a really large CSV or have a bucket with a huge number of files.
For now though, you can view the latest code here, and try the latest demo here. Enjoy!